English Philology, University of Oulu, Finland, steven.coats@oulu.fi
ICAME 41
University of Heidelberg, May 2020
Outline¶
YouTube and transcript files
Corpus creation from the API (Application Programming Interface) and scraping
US corpus, Canada corpus, British Isles corpus
Example/application: Analysis of articulation rate in the US (Coats 2019b)
Caveats, summary, future outlook
YouTube as a data source in language and linguistics studies¶
Billions of YouTube videos, many with data that may be useful for studies in sociolinguistics, dialectology, phonetics, etc.
Videos downloadable, audio signal can be extracted, captions files (user-uploaded or automatically-generated) exist (for many videos) and can be downloaded
Metadata such as location, occasion, interaction type, etc. can often be inferred
Data accessible through API and the web
YouTube captions¶
Videos may have multiple captions files: user-uploaded captions, auto-generated captions created using automatic speech recognition (ASR), or both, or neither
User-uploaded captions can be manually created or generated automatically by 3rd-party ASR software
Auto-generated captions are generated by Google's speech-to-text service
YouTube automatic speech-to-text captions¶
First ASR captions 2009 (Google 2009)
Advances in neural-network-based automatic speech-to-text transcription increase transcript accuracy (Dahl et al. 2012, Jaitly et al. 2012, Liao, McDermott & Senior 2014)
Google reports WER (word error rates) between 4.1%–5.6% for recent neural-network based ASR models (Chiu et al. 2018; cf. Ziman et al. 2018)
WER higher for videos
Example video¶
srv1¶

srv2¶

srv3¶

ttml¶

WebVTT file¶
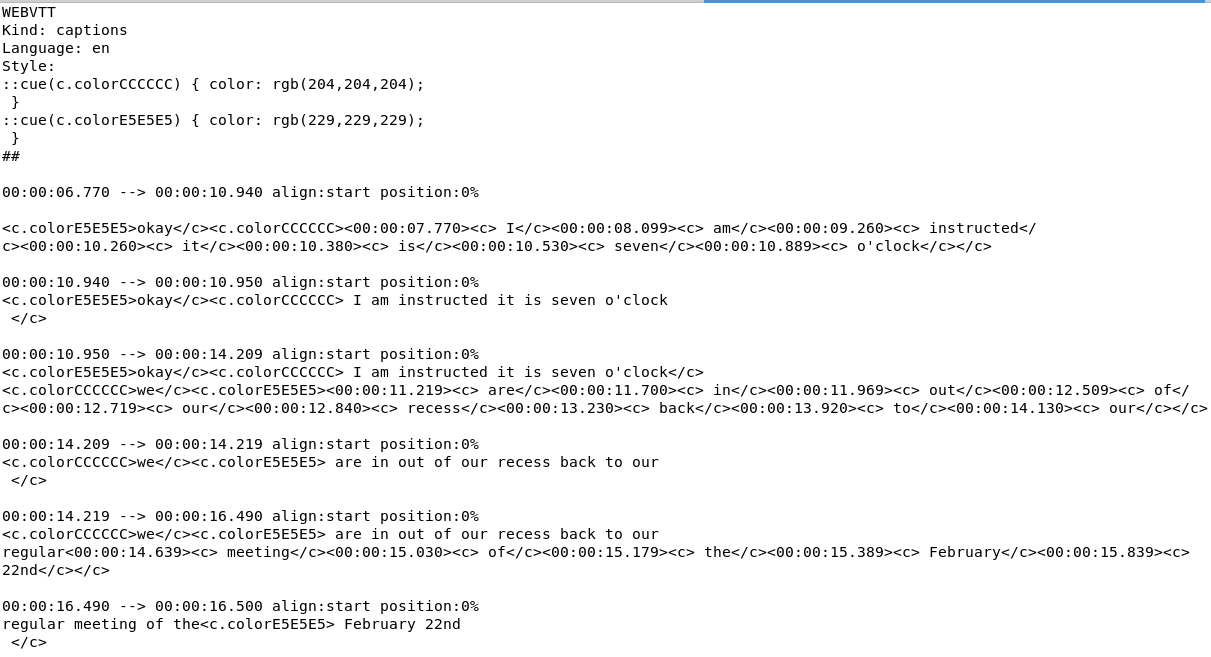
- Text extraction: ttml and srv1 files
- Word timings: srv2, srv3 or vtt files
- VTT files need to be parsed more carefully (words repeated in cue and in tag)
YouTube's API¶
Provides access to videos, channels, and playlists that match search criteria
Can also be used to get activity summaries, automatically-generated video categories, image thumbnails, comments, like/dislike ratios, etc.
Data is returned in JSON format
Access limit via quota, all calls to API have a quota cost
YouTube API quota cost¶
- Search for a playlist, video, or channel: 100 units per page of results (increased from 50, Nov. 19)
- List metadata (such as ID code or URL) associated with a specific resource (video, playlist, channel): 3 units per resource
- List all captions files associated with a specific video: 50 units
- Retrieve a specific captions file: 200 units
YouTube's API: Quotas¶
- April 2016: Default daily quota reduced from 50,000,000 units to 1,000,000 units
- January 2019: Default daily quota reduced from 1,000,000 units to 10,000 units
- It is less feasible to get everything through the YouTube API
- One can request a larger quota by providing detailed information about planned data use and a video demonstrating API access
- Google doesn't like your idea? Increase not granted and API access revoked
Creating a corpus of geo-located language¶
Identify content of interest (e.g. local government channels) from the API or by scraping
Get the captions files (and video/audio) using YouTube-DL
Get geographical locations
Focus on US local government/civic organizations¶
Videos are often public meetings of elected representatives at town/city/county/state level: advantages in terms of representativeness and comparability
Speaker place of residence (cf. videos collected based on place-name search alone)
Topical contents comparable
Communicative contexts comparable
Audio quality often high
Strategy 1 (e.g. Coats 2019a, 2019b)¶
Make calls to the API with search terms that include place names
Search for channels
"Alabama city council", "Arizona city council", "Arkansas city council", etc.
New quota limit makes this unrealistic
Strategy 2: Use automated browser script with YouTube search¶
Python module Selenium for browser automation
Imitate a user interacting with YouTube's web search interface
Check tag attributes to get channel URLs
Strategy 3: Scrape websites for links to YouTube Channels¶
Many homepages of municipalites have links to social media presence
Scrape pages to get links to YouTube channels
Filtering¶
- Channels may need to be checked manually to remove false positives
Youtube-DL¶
Open-source software for YouTube scraping
Input: List of YouTube video or channel IDs
Downloads specified content (captions), saved as files
IP Address blocking¶
YouTube will block IPs for 48, 72 or more hours if too many http requests are made, therefore:
Change IP address after every 1000 http requests
- Getting a large number of IP addresses (e.g. through a VPN) is expensive
Tor (Loesing, Murdoch & Dingledine 2010)
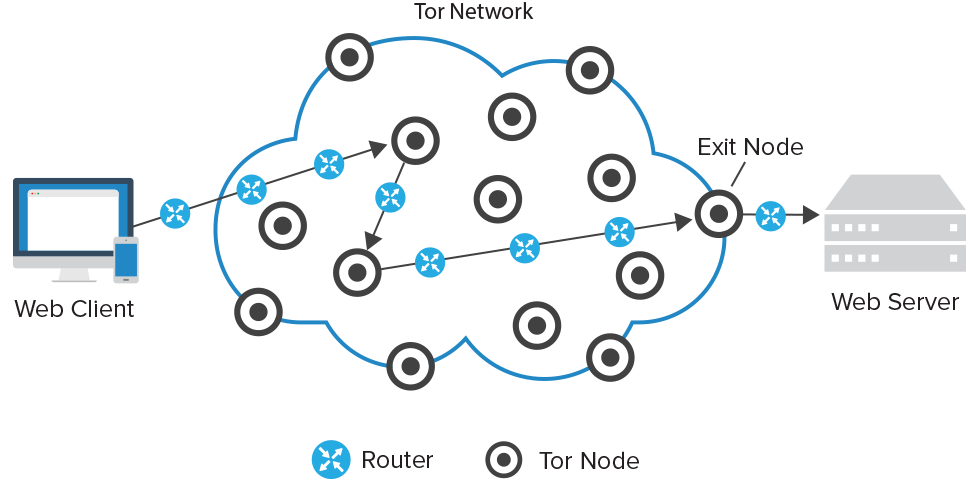
- Open source software for anonymous internet use
- Tor exit node randomized every 1000 calls to YouTube
Geographical location¶
Some videos have a geographical location tag (lat-long coordinates) assigned by the user, but most don't
Infer geographical location based on search term and channel title
Locations¶
- Use regex to parse channel names
- "cityofmontgomery" -> "city of montgomery"
- Pass the string with the search state to geocoder: "city of montgomery, Alabama"
- geopy (Esmukov et al. 2018), Google Places (or other) API
- returns latitude-longitude coordinates
Text Parsing¶
- Downloaded captions files need to be parsed from XML/WebVTT to text
- Optional: PoS tagging, other NLP processing
US corpus (Coats 2019a, 2019b)¶
- 579 channels, 53,743 .vtt files
- After filtering: 49,345 videos, 28,166.77 hours of video, 235,824,795 words
US corpus addition¶
- US Census Bureau: List of 91,386 local government units (cities, towns, counties, school districts, utility districts)
- 35,924 websites scraped
- 2,376 YouTube channels
- 335,017 videos from all 50 states, 153,926 hours of video, 1,236,298,290 words
Canada corpus¶
- List of websites of 3,401 Canadian administrative entities created from various sources
- Websites scraped and YouTube searched with automated browser for each municipality name
- 443 channels
- 40,966 videos from all 13 provinces/territories, 15,321 hours of video, 123,499,887 words
North America corpus: channel locations¶
1.6 billion words, 3,211 channels, 427,652 videos, 195,641 hours of video
British Isles corpus¶
- List of 413 local units: 317 in England (55 unitary authorities, 193 non-metropolitan districts, 36 metropolitan boroughs, 32 London boroughs, Isles of Scilly), 32 in Scotland, 22 in Wales, 11 in Northern Ireland, 31 in Republic of Ireland
- Automated search of authority name + "Council"
- 365 channels
- 28,485 videos, 5875 hours of video, 47,462,144 words
Potential applications¶
Analysis of
- Lexical variation
- Morphosyntactic variation (cf. Orton et al. 1978, Szmrecsanyi 2011, Grieve 2016)
- Articulation rate (Coats 2019b) and pause
- Pragmatic categories in conversation, as manifest in token or PoS sequences (e.g. repair initiation "no I mean", apologies such as "you know I", "sorry but I", etc.)
- Spatial distribution of concepts/semantic fields
- With audio: vowel formant extraction, voice quality measures, etc.
Articulation rate in American English (Coats 2019b)¶
- For each channel location: Calculate the mean intra-utterance continuous articulation rate based on individual word timings for all videos from that channel
- Verify method by analyzing the acoustic signal with a Praat script (De Jong & Wempe 2009)
- Use the local spatial autocorrelation statistic Getis-Ord G*i to infer large-scale patterns of difference or similarity (Ord & Getis 1992; Getis & Ord 1995, cf. Grieve 2016; Grieve, Speelman & Geeraerts 2011)
Weights matrices: polygon continuity binary; 5, 10, 25, and 50 nearest-neighbor binary; and inverse distance with cutoffs of 200km and 100km)
Contractions in the British Isles¶
Ratio of contracted to uncontracted forms; 50 nearest-neighbor binary weights matrix, Getis-Ord G*i
Checking transcript accuracy¶
- Compare ASR transcripts with officially authorized transcripts of same recordings
- Get all ASR transcripts of meetings of Philadelphia City Council
- Get all corresponding manual transcripts from Philadelphia City Council's website
- Compare word frequencies with log-likelihood test
- Result: 5% of word types have significant differences in frequency
Caveats¶
- Method gets aggregate transcripts for entire videos
- No diarization for individual speakers
- Google ASR algorithm changes: transcript quality not necessarily comparable over time
- Algorithm mostly omits fillers such as uh, um, like
- Different average WERs for different groups of speakers (females, Scots) (Tatman 2017)
Summary and outlook¶
- Corpora can be created from YouTube transcripts via automated methods
- Compare with large corpora of written language
- Automatically identify higher-quality (more accurate) transcripts
- Automatically annotate speaker variables?
- Corpora for other regions/languages
That's all! Thanks for listening!¶
References¶
Chiu, C.-C., Sainath, T. N., Wu, Y., Prabhavalkar, R., Nguyen, P., Chen, Z., Kannan, A., Weiss, R. J., Rao, K., Gonina, E., Jaitly, M., Li, B., Chorowski, J. & Bacchiani, M. (2018). State-of-the-art speech recognition with sequence-to-sequence models. arXiv:1712.01769v6 [cs.CL].
Coats, S. (2019a). A corpus of regional American language from YouTube. In Navarretta, C. et al. (Eds.), Proceedings of the 4th Digital Humanities in the Nordic Countries Conference, Copenhagen, Denmark, March 6–8, 2019 (pp. 79–91). Aachen, Germany: CEUR.
Coats, S. (2019b). Articulation rate in American English in a corpus of YouTube videos. Language and Speech. https://doi.org/10.1177/0023830919894720
Dahl, G. E., Yu, D., Deng, L. & Acero, A. (2012). Context-dependent pre-trained deep neural networks for large-vocabulary speech recognition. IEEE Transactions on Audio, Speech, and Language Processing 20(2), 30–42.
De Jong, N.H. & Wempe, T. (2009). Praat script to detect syllable nuclei and measure speech rate automatically. Behavior research methods, 41(2), 385–390.
Esmukov, K., et al. (2018). Geopy. [Python module]. https://github.com/geopy/geopy
FFmpeg Developers. (2019). ffmpeg tool (Version 4.1.3) [Computer software]. http://ffmpeg.org
Getis, A. & Ord, J. K. (1992). The Analysis of Spatial Association by Use of Distance Statistics. Geographical Analysis. 24(7), 189–206.
Google. (2009). Automatic captions in YouTube. https://googleblog.blogspot.com/2009/11/automatic-captions-in-youtube.html
Grieve, J. (2016). Regional variation in written American English. Cambridge, UK: Cambridge University Press.
Grieve, J., Speelman, D. & Geeraerts, D. (2011). A statistical method for the identification and aggregation of regional linguistic variation. Language Variation and Change 23, 193–221.
Halpern, Y., Hall, K. B., Schogol, V., Riley, M., Roark, B., Skobeltsyn, G. & Bäuml, M. (2016). Contextual prediction models for speech recognition. In Proceedings of INTERSPEECH 2017, 2338–2342.
Jaitly, N., Nguyen, P., Senior, A. & Vanhoucke, V. (2012). Application of pretrained deep neural networks to large vocabulary speech recognition. Proceedings of INTERSPEECH 2012, 2578–2581.
Liao, H., McDermott, E. & Senior, A. (2013). Large scale deep neural network acoustic modeling with semi-supervised training data for YouTube video transcription. Proceedings of the 2013 IEEE Workshop on Automatic Speech Recognition and Understanding, 368–373
Loesing, K., Murdoch, S. J., & Dingledine, R. (2010). A case study on measuring statistical data in the Tor anonymity network. In R. Sion et al. (Eds.), Financial Cryptography and Data Security: FC 2010 Workshops, RLCPS, WECSR, and WLC 2010 Tenerife, Canary Islands, Spain, January 2010, Revised Selected Papers, 203–215.
Ord, J. K. & Getis, A. (1995). Local spatial autocorrelation statistics: Distributional issues and application. Geographical Analysis 27(4), 286–306.
Orton, H., Sanderson, S. & Widdowson, J.D.A. (1978). The Linguistic Atlas of England. London and Atlantic Highlands, New Jersey: Croom Helm.
Szmrecsanyi, B. (2011). Corpus-based dialectometry: A methodological sketch. Corpora 6(1), 45–76.
Yen, C.-H., Remite, A. & Sergey M. (2019). Youtube-dl [Computer software]. https://github.com/rg3/youtube-dl/blob/master/README.md