The Corpus of British Isles Spoken English (CoBISE) is a corpus of geolocated automatic speech recognition (ASR) YouTube transcripts from the United Kingdom and Ireland, created for the study of linguistic and interactional phenomena in contemporary English. Transcripts are linked to videos accessible through the YouTube platform, allowing the study of multimodal phenomena.
The corpus was created from 38,680 ASR transcripts from 497 YouTube channels, corresponding to more than 12,800 hours of video. The size of the corpus is 111,563,614 tokens. The channels sampled in the corpus are associated with local government entities such as county or city councils. The transcripts are primarily of recordings of public meetings, although other genres are also present. Video transcripts have been assigned exact latitude-longitude coordinates using a geocoding script.
Format and metadata
The corpus exists in two versions: one in which the transcripts have not been annotated, and one in which word tokens have been annotated with part-of-speech tags and timing. Data is in tabular form in csv format (with the pipe character "|" as a separator). The columns of the table are 'country', 'channel_title', 'channel_id', 'video_title', 'video_id', 'video_length','location','nr_words', 'text_pos', (or 'text', in the untagged version), and 'latlong'. Each row corresponds to an individual transcript (see excerpt below).
Transcripts are in the 'text' column (or 'text_pos', for the tagged version). Tagging was done with spaCy and the Penn Treebank tagset. Tagged tokens have the format "token_POS_10.0", where "token" is the transcribed lexical item, "POS" the tag, and "10.0" the time offset in seconds from the start of the corresponding video.
| country | channel_title | channel_id | video_title | video_id | video_length | location | nr_words | text_pos | latlong | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | England | Adur and Worthing Councils | UCzO8eEeKaOb90S3_XbOp2Xg | Hamstring Curl - Get Active | L_MeAKFAdfM | 198.39 | Business Park, 9 Commerce Way, Lancing BN15 8TA, UK | 325 | the_DT_0.149 next_JJ_0.45 exercise_NN_0.75 is_VBZ_1.079... | (50.823891, -0.3376343) |
| 1 | England | Adur and Worthing Councils | UCzO8eEeKaOb90S3_XbOp2Xg | #HousingDay 2015 live debate | T5upcg1ObuI | 1848.21 | Business Park, 9 Commerce Way, Lancing BN15 8TA, UK | 5175 | we_PRP_0.38 've_VBP_0.38 been_VBN_1.38 talking_VBG_1.62... | (50.823891, -0.3376343) |
| 2 | England | Adur and Worthing Councils | UCzO8eEeKaOb90S3_XbOp2Xg | Front Raise - Get Active | HZ8nLNRXGOI | 248.48 | Business Park, 9 Commerce Way, Lancing BN15 8TA, UK | 469 | the_DT_0.149 next_JJ_0.359 exercise_NN_0.659 is_VBZ_0.93 ... | (50.823891, -0.3376343) |
| 3 | England | Adur and Worthing Councils | UCzO8eEeKaOb90S3_XbOp2Xg | #OurDay _ Adur & Worthing Councils | kIMvQJnjeTg | 163.069 | Business Park, 9 Commerce Way, Lancing BN15 8TA, UK | 274 | [Music]_XX_0.16 why_WRB_6.02 stop_VB_7.02 r6_NN_7.35 ... | (50.823891, -0.3376343) |
| 4 | England | Adur and Worthing Councils | UCzO8eEeKaOb90S3_XbOp2Xg | Cat Stretch - Get Active | cEz-w2z1ZBQ | 243.78 | Business Park, 9 Commerce Way, Lancing BN15 8TA, UK | 471 | the_DT_0.149 next_JJ_0.39 stretch_NN_0.81 is_VBZ_1.05 ... | (50.823891, -0.3376343) |
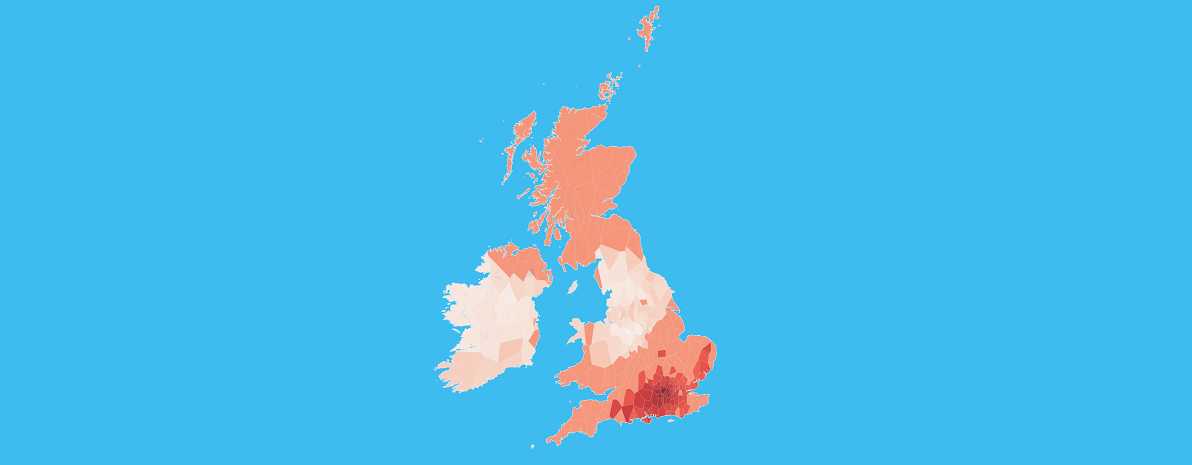
Locations
Channels have been sampled in England, Scotland, Wales, Northern Ireland, and the Republic of Ireland. The map below shows the locations, names, and sizes of the sampled channels.
Sample script
Corpus hits can be presented as a data table with links to the videos at the time of utterance. This Python script, for example, will
retrieve all instances of the sequence "I daresay" in the PoS-tagged text in the table cobise_df:
import re
hits = []
pat1 = re.compile("((\\w+_\\S+_\\S+\\s){3}i_\\w+_\\S+ daresay_\\w+_\\S+\\s(\\w+_\\S+_\\S+\\s){3})",re.IGNORECASE)
for i,x in cobise_df.iterrows():
if pat1.search(x["text_pos"]):
finds1 = pat1.findall(x["text_pos"])[0]
seq = " ".join([x.split("_")[0] for x in finds1[0].split()])
time = finds1[0].split()[0].split("_")[-1]
hits.append((x["country"],x["channel_title"],seq,"https://youtu.be/"+x["video_id"]+"?t="+str(round(float(time)-3))))
pd.DataFrame(hits)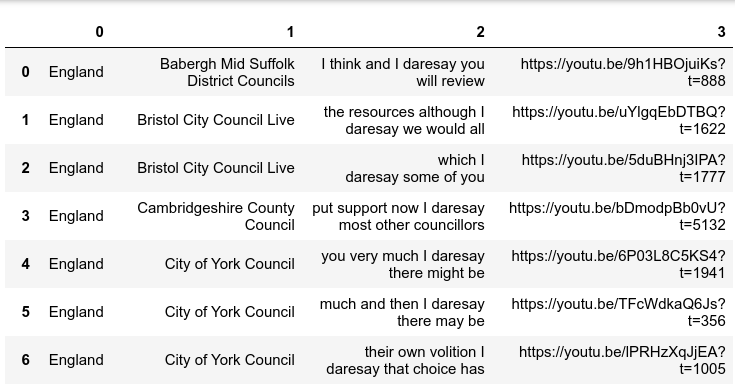
Access
The corpus is available free of charge for the purposes of research, education, and scholarship. Users may not redistribute the corpus or use it for commercial purposes. Users are individually responsible for compliance with these terms.
CoBISE can be downloaded from the Harvard Dataverse here.
Citation
To cite the corpus, please use
- Coats, Steven. 2022. The Corpus of British Isles Spoken English (CoBISE): A new resource of contemporary British and Irish speech. In Karl Berglund, Matti La Mela, and Inge Zwart (eds.), Proceedings of the 6th Digital Humanities in the Nordic and Baltic Countries Conference, Uppsala, Sweden, March 15–18, 2022, 187–194. Aachen, Germany: CEUR.
You may also be interested in the Corpus of North American Spoken English, the Corpus of Australian and New Zealand English, and the Corpus of German Speech.