The Corpus of North American Spoken English (CoNASE) is a 1.29-billion-word corpus of geolocated automatic speech recognition (ASR) YouTube transcripts from the United States and Canada. It was created for the study of lexical, grammatical, and discourse-pragmatic phenomena of spoken language, including their geographical distribution, in North American English. The size of the corpus allows rare phenomena to be considered, and because the annotation includes the video IDs of transcripts, search hits can be manually inspected and video or audio data can be accessed.
Corpus description
The corpus was created from 301,846 ASR transcripts from 2,572 YouTube channels, corresponding to 154,041 hours of video. The size of the corpus is 1,294,885,016 word tokens. The channels sampled in the corpus are associated with local government entities such as town, city, or county boards and councils, school or utility districts, regional authorities such as provincial or territorial governments, or other governmental organizations. The transcripts are primarily of recordings of public meetings, although other genres are also present. Video transcripts have been assigned exact latitude-longitude coordinates using a geocoding script.
Format and metadata
The corpus exists in two versions: one in which the transcripts have not been annotated, and one in which word tokens have been annotated with part-of-speech tags and timing. Data is in tabular form in csv format (with the pipe character "|" as a separator). The columns of the table are 'country', 'state', 'channel_title', 'video_title', 'video_id', 'name', 'type', 'channel_id', 'channel_username', 'video_length', 'location', 'address', 'nr_words', 'text_pos' (or 'text', in the untagged version), and 'latlong'. Each row corresponds to an individual transcript (see excerpt below).
The columns 'name' and 'type' correspond to US Census Bureau designations for the government entity the channel represents (see Coats, in review). Transcripts are in the 'text' column (or 'text_pos', for the tagged version). Tagging was done with spaCy and the Penn Treebank tagset. Tagged tokens have the format "token_POS_10.0", where "token" is the transcribed lexical item, "POS" the tag, and "10.0" the time offset in seconds from the start of the corresponding video.
| country | state | channel_title | video_title | video_id | name | type | channel_id | channel_username | video_length | location | address | nr_words | text_pos | latlong | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | USA | Alabama | Baldwin County Alabama | Loxley School | KAFtEkKE_ik | COUNTY OF BALDWIN | general purpose | UCVEowdBqDvlT_TJDjf8YuyA | BCCommission | 1651.38 | Baldwin County, AL, USA | Baldwin County, AL, USA | 3513 | the_DT_25.619 Baldwin_NNP_26.619 County_NNP_27... | (30.6010744, -87.77633329999999) |
| 1 | USA | Alabama | Baldwin County Alabama | 2019 Baldwin County Sewer Utilities Informatio... | 6KvmxXRoMGA | COUNTY OF BALDWIN | general purpose | UCVEowdBqDvlT_TJDjf8YuyA | BCCommission | 6110.09 | Baldwin County, AL, USA | Baldwin County, AL, USA | 16090 | welcome_UH_1.37 everybody_NN_2.37 glad_JJ_3.89... | (30.6010744, -87.77633329999999) |
| 2 | USA | Alabama | Baldwin County Alabama | Heritage Museum of Baldwin County Alabama | bGL_FlSulZ4 | COUNTY OF BALDWIN | general purpose | UCVEowdBqDvlT_TJDjf8YuyA | BCCommission | 1255.31 | Baldwin County, AL, USA | Baldwin County, AL, USA | 2318 | located_VBN_22.039 in_IN_23.039 the_DT_23.13 t... | (30.6010744, -87.77633329999999) |
| 3 | USA | Alabama | Baldwin County Alabama | AL State Veterans Memorial Cemetery at Spanish... | BX18sxhdL5Y | COUNTY OF BALDWIN | general purpose | UCVEowdBqDvlT_TJDjf8YuyA | BCCommission | 4376.31 | Baldwin County, AL, USA | Baldwin County, AL, USA | 7991 | good_JJ_15.94 morning_NN_16.94 everyone_NN_17.... | (30.6010744, -87.77633329999999) |
| 4 | USA | Alabama | Baldwin County Alabama | USO Canteen Dance Re-enactment | VqCvFSku9Es | COUNTY OF BALDWIN | general purpose | UCVEowdBqDvlT_TJDjf8YuyA | BCCommission | 3893.26 | Baldwin County, AL, USA | Baldwin County, AL, USA | 6846 | [Music]_XX_5.1 [Music]_XX_14.86 [Music]_XX_104... | (30.6010744, -87.77633329999999) |
Locations
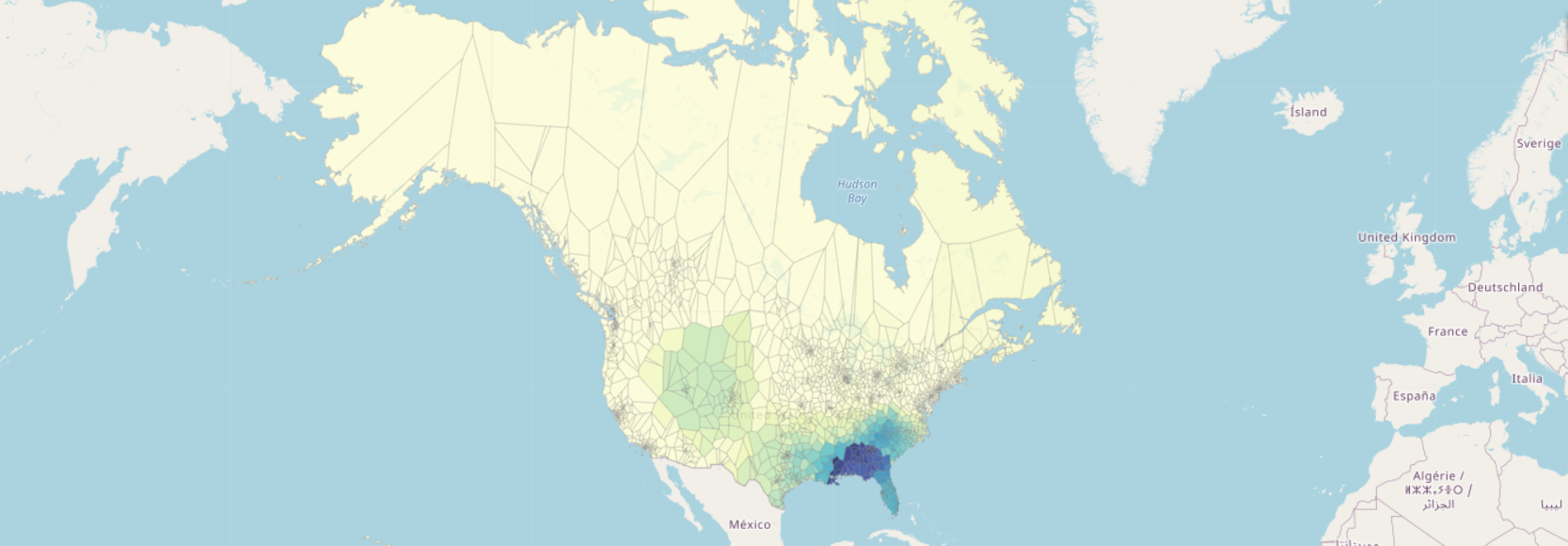
Channels have been sampled in all of the 50 United States, the District of Columbia, and all 13 Canadian Provinces or Territories. The map below shows the locations, names, and sizes of the sampled channels.
Sample script
Corpus hits can be presented as a data table with links to the videos at the time of utterance. This Python script will
retrieve all instances of "is there any way" in the PoS-tagged text in the table conase_df:
import re
hits = []
pat1 = re.compile("is_\\w+_\\S+ there_\\w+_\\S+ any_\\w+_\\S+ way_\\w+_\\S+",re.IGNORECASE)
for i,x in conase_df.iterrows():
if pat1.search(x["text_pos"]):
finds1 = pat1.findall(x["text_pos"])[0]
seq = " ".join([x.split("_")[0] for x in finds1.split()])
time = finds1.split()[0].split("_")[-1]
hits.append((x["state"],x["channel_title"],seq,"https://youtu.be/"+x["video_id"]+"?t="+str(round(float(time)-3))))
pd.DataFrame(hits)
Access
The corpus is available free of charge for the purposes of research, education, and scholarship. Users may not redistribute the corpus or use the corpus for commercial purposes. The corpus is available through the Harvard Dataverse here. Please also see the Corpus of British Isles Spoken English, created using similar methods, here.
Citation and contact
To cite the corpus, please use
- Coats, Steven. 2023. Dialect corpora from YouTube. In Beatrix Busse, Nina Dumrukcic, and Ingo Kleiber (eds.), Language and linguistics in a complex world, 79–102. Berlin: de Gruyter. https://doi.org/10.1515/9783111017433-005
steven.coats at oulu.fi, https://cc.oulu.fi/~scoats