The Corpus of German Speech (CoGS) is a 51-million-word corpus of geolocated automatic speech recognition (ASR) YouTube transcripts from local government channels in Germany, created for the study of lexical, grammatical, and discourse-pragmatic phenomena of spoken language. Annotation includes individual word timings and video IDs of transcripts, making it easy to instantly view the video(s) for any given search. CoGS represents a rich resource for the study of language and communication in Germany, but given the content of the transcripts, may also be of interest to students and researchers in diverse digital humanities and social science fields such as cultural studies, geography, political science, sociology, urban studies and planning, or tourism studies, among others.
Corpus description
The corpus was created from 39,495 ASR transcripts from 1,313 YouTube channels, corresponding to more than 7,223 hours of video. The size of the corpus is 50,514,575 tokens. The channels sampled in the corpus are associated with local government entities, mostly city governments. The transcripts are from a range of video types. Metadata includes exact latitude-longitude coordinates for corresponding municipalities, making geographical analysis of language use possible.
Format and metadata
The corpus exists in two versions: one in which the transcripts have not been annotated, and one in which word tokens have been annotated with part-of-speech tags and timing. Data is in tabular form in csv format (with the pipe character "|" as a separator). The columns of the table are 'Bundesland', 'Gemeinde', 'channel_title', 'channel_url', 'video_title', 'video_id', 'upload_date', 'video_length', 'location','nr_words','text_pos' (or 'text', in the untagged version), and 'latlong'. Each row corresponds to an individual transcript (see excerpt below).
Transcripts are in the 'text_pos' column (or the 'text' column, for the untagged version). Tagging was done with spaCy and the Stuttgart-Tübingen tagset tagset. Tagged tokens have the format "token_POS_10.0", where "token" is the transcribed lexical item, "POS" the tag, and "10.0" the time offset in seconds from the start of the corresponding video.
| Bundesland | Gemeinde | channel_name | channel_url | video_id | video_title | upload_date | video_length | nr_words | location | latlong | text_pos | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 27062 | Nordrhein-Westfalen | Krefeld | Krefeld | https://www.youtube.com/user/stadtkrefeld | G2PilMB9-OY | Freier Eintritt KinderJugendliche KWMHLHE | 20200207 | 94.140 | 166 | Von-der-Leyen-Platz 147798 Krefeld | (51.33262, 6.56238) | [Musik]_VVFIN_0.0 wir_PPER_4.46 würden_VAFIN_5.46 uns_PPER_5.819 sehr_ADV_6.089... |
| 1937 | Baden-Württemberg | Friedrichshafen | Stadt Friedrichshafen | https://www.youtube.com/user/StadtFN | fbKNjM05gN4 | KRATZ- UND BISSFEST Nr. 9 Der Holzfisch | 20200514 | 190.560 | 197 | Adenauerplatz 188045 Friedrichshafen | (47.654166666667, 9.4791666666667) | [Musik]_NN_3.74 ja_ADV_18.38 ja_ADV_20.32 herzlich_ADJD_21.15 willkommen_ADJD_22.15... |
| 6548 | Baden-Württemberg | Stuttgart | Landeshauptstadt Stuttgart | https://www.youtube.com/user/stuttgartlhs | PiSYYfbGmHs | #Futureproofchallenge Aftermovie | 20211004 | 124.949 | 168 | Marktplatz 170173 Stuttgart | (48.775555555556, 9.1827777777778) | [Musik]_NN_0.0 2021_CARD_1.3 feiern_VVINF_2.3 stuttgart_NE_3.139 und_KON_3.83... |
| 35747 | Rheinland-Pfalz | Ober-Olm | Ober-Olm | https://www.youtube.com/channel/UCp9tbm4RFK92G2VVssy-DUA | J9TWgS2_JhM | Abendgedanken am 16.01.2022 mit Diakon Schmuck _ Ober-Olm | 20220116 | 290.200 | 699 | Pariser Straße 11055268 Nieder-Olm | (49.936944444444, 8.1888888888889) | die_ART_0.829 schlagzeile_NN_1.829 sonntags_ADV_2.7 jesus_NE_3.47 rettet_VVFIN_4.47... |
| 35077 | Rheinland-Pfalz | Bad Dürkheim | Bad Dürkheim | https://www.youtube.com/user/StadtBadDuerkheim | fHhjwkkGnoM | Bericht über die Sitzung des Bad Dürkheimer Stadtrates am 27. Oktober 2020 | 20201103 | 589.370 | 1493 | Mannheimer Straße 2467098 Bad Dürkheim | (49.459444444444, 8.1680555555556) | ja_PTKANT_0.0 in_APPR_0.48 wunderschönen_NN_0.63 guten_ADJA_1.02 abend_NN_1.079... |
Locations
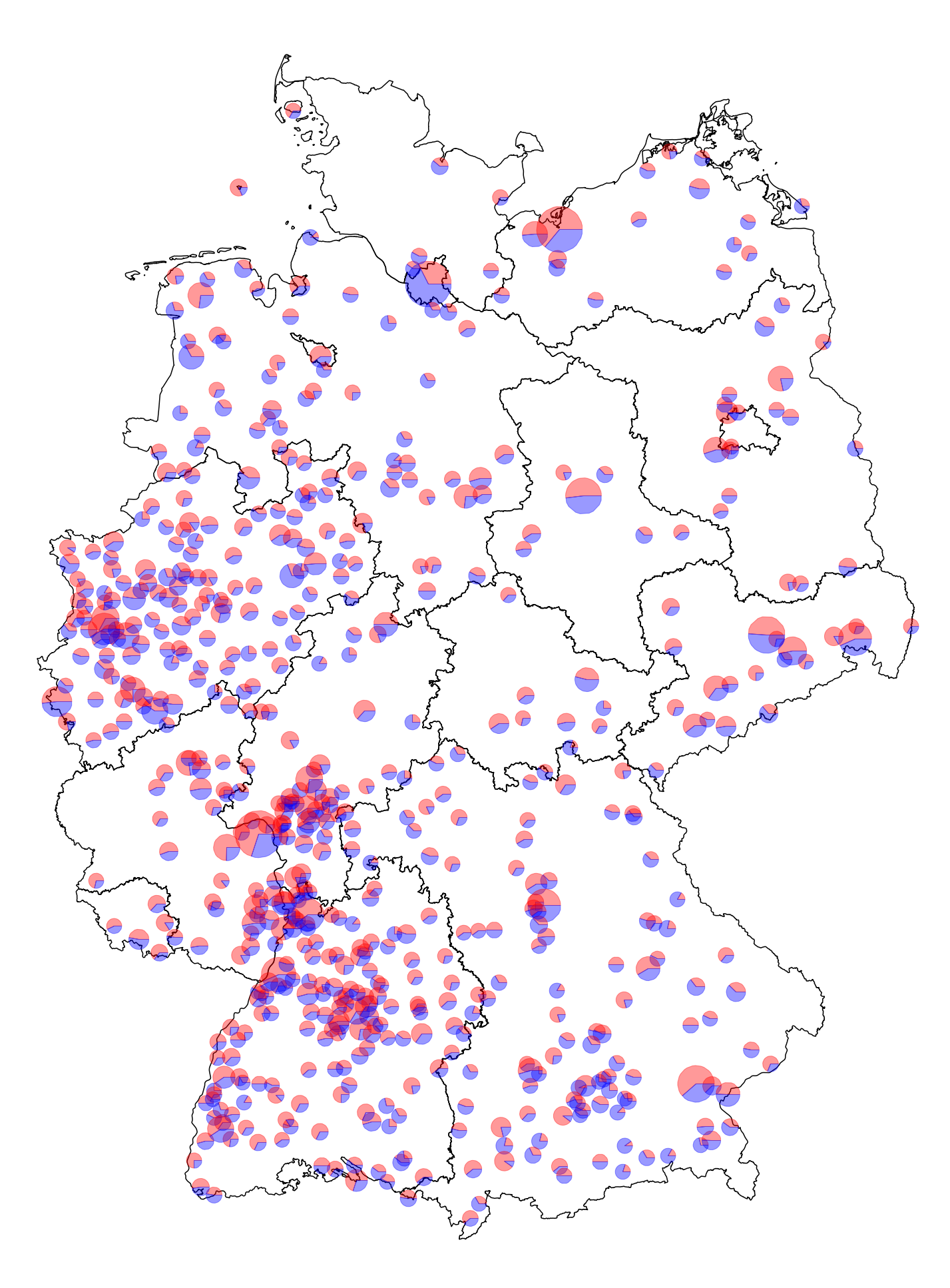
The map below shows the locations, names, and sizes of the sampled channels.
Sample script
Corpus hits can be presented as a table with links to the videos at the times of utterance, permitting quick manual filtering and annotation
of audio and video material. This Python script will
retrieve all instances of "ach du meine" in the PoS-tagged text in the table cogs_df with the immediate context:
import re
hits = []
pat1 = re.compile("((\\w+_\\S+_\\S+\\s){3}ach_\\w+_\\S+\\sdu_\\w+_\\S+\\smeine_\\w+_\\S+\\s(\\w+_\\S+_\\S+\\s){3})",re.IGNORECASE)
for i,x in cogs_df.iterrows():
if pat1.search(x["text_pos"]):
finds1 = pat1.findall(x["text_pos"])[0]
seq = " ".join([x.split("_")[0] for x in finds1[0].split()])
time = finds1[0].split()[0].split("_")[-1]
hits.append((x["country"],x["channel_name"],x["video_title"],seq,"https://youtu.be/"+x["video_id"]+"?t="+str(round(float(time)-3))))
pd.DataFrame(hits)
Access
The corpus is available free of charge for the purposes of research, education, and scholarship. Users may not redistribute the corpus or use the corpus for commercial purposes. The corpus is available through the Harvard Dataverse here. Please also see the Corpus of North American Spoken English and the Corpus of British Isles Spoken English, created using similar methods.
Citation
To cite the corpus, please use
- Coats, Steven. 2022. Corpus of German Speech (CoGS). https://cc.oulu.fi/~scoats/CoGS.html.